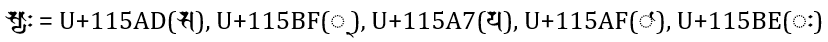CBETA API 字數統計規則
2026-02-06
目次
- 1 前言
- 2 共同原則
- 3 chars, chars_no_spaces (字元數)
- 4 「中文字數」與「英數字數」共同原則
- 5 標點、符號不算
- 6 要列入計算的特殊字元
- 7 英數字以 word 計算,而不是 characters
1 前言
字數統計分四類:
- chars 字元數 (含空格)
- chars_no_spaces 字元數 (不含空格)
- cjk_chars 中、日、韓、悉曇字、蘭札體
- en_words 英文、梵巴文 詞數
2 共通原則
2.1 缺字標記 <g> 算一個字
- 計入 chars, chars_no_spaces, cjk_chars
- 包含:悉曇字、蘭札體
2.2 <unclear> 算一個字
- 原書字跡不清、難以辨識的字,在 CBETA XML 標記為 <unclear>,這也算一個字。
- 計入 chars, chars_no_spaces, cjk_chars
3 chars, chars_no_spaces (字元數)
- 這些都列入計算:原書用字、CBETA 選字、對校本用字、原書校注、CBETA 修訂校注、CBETA 新增校注
- 英文 book 算四個字元
4 「中文字數」與「英數字數」共同原則
4.1 校注 不算
4.2 夾注 要算
4.3 <docNumber> 不算
例如大正藏:No.72[No.26(155),Nos.73,74,No.125(27.3)]在 CBETA XML 裡標記為 <docNumber>.
使用者要的應該是「典籍內文的字數」,
而 docNumber 其實是大正藏加上去的,
並不是這一部典籍裡的字數。
例如我們通常說心經有幾個字, 是不會想要把 docNumber 加上去的。
5. 標點、符號不算
cjk_chars 不計算以下字元
| Unicode Name | Unicode Range | CBETA 使用字元 | Note |
|---|---|---|---|
| C0 Controls and Basic Latin | 0000-007F | U+0009, U+000A, U+0020 "#$%&'()\*+,-./0123456789:;\<=\>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ\[\\\]^\_\`abcdefghijklmnopqrstuvwxyz{|}\~ | |
| C1 Controls and Latin-1 Supplement | 0080-00FF | §°±·Ñ×Üàáâäæéêíïñóôöùúûü | |
| Spacing Modifier Letters | 02B0-02FF | ʼˇˋ | |
| Combining Diacritical Marks | 0300-036F | U+0310 ̐ | |
| General Punctuation | 2000-206F | – — ’ “ ” … ‧ ※ ⁉ | |
| Number Forms | 2150-218F | ⅠⅡⅢⅣⅤⅥⅦⅧⅨⅩ | |
| Arrows | 2190-21FF | ←↑→↓↖↗↘↙ | |
| Mathematical Operators | 2200-22FF | ∕√∞∟∠∴∵≡⊕⊙⊥ | |
| Enclosed Alphanumerics | 2460-24FF | ①②③④⑤⑥⑦⑧⑨⑩ | |
| Box Drawing | 2500-257F | | ─│┌┐└┘├┤┬┴┼═║╭╮╯╰╱╲╳ | |
| Block Elements | 2580-259F | ▔■ | |
| Geometric Shapes | 25A0-25FF | □▲△▽◇○◎●◐◑ | |
| Miscellaneous Symbols | 2600-26FF | ☆ | |
| Latin Extended-C | 2C60-2C7F | CBETA 目前未使用 | |
| CJK Symbols and Punctuation | 3000-3002 | {U+3000}、。 | |
| 3004 | CBETA 目前未使用 | 〄 | |
| 3008-3011 | 〈〉《》「」『』【】 | ||
| 3014-301F | 〔〕 | ||
| 3030 | CBETA | 〰 | |
| 3037 | CBETA 目前未使用 | 〷 | |
| 303D-303F | CBETA 目前未使用 | 〽〾〿 | |
| CJK Compatibility Forms | FE30-FE4F | ︵︶﹁﹂﹄﹏ | |
| Small Form Variants | FE50-FE6F | ﹐﹑﹒﹔﹕﹖﹗﹘﹙﹚﹛﹜﹝﹞﹟﹠﹡﹢﹣﹤﹥﹦﹨﹩﹪﹫ | |
| Halfwidth and Fullwidth Forms | FF01-FF0F | !&'()*+,-./ | |
| FF10-FF19 | 0123456789 | ||
| FF1A-FF20 | :;<=>?@ | ||
| FF21-FF3A | ABCDEFGHIJKLMNOPRSTUVWXYZ | ||
| FF3B-FF40 | [\]^_` | ||
| FF41-FF5A | abcdeiu | ||
| FF5B-FF64 | |}~ |
6 要列入計算的特殊字元
| Unicode | Unicode Name | 說明 |
|---|---|---|
| 3003 〃 | Ditto Mark | 重文符號,例如「漸〃」算2個字。 |
| 3005 々 | IDEOGRAPHIC ITERATION MARK | 重文符號,例如「人々」算2個字。 |
| 3006 〆 | IDEOGRAPHIC CLOSING MARK |
CBETA 目前未使用此字元。 參考: https://www.letsgojp.com/archives/393819 看到「〆shime」時,大家都以為是簡寫的符號吧?其實這個字是和製漢字,部首為「丿部」,被收錄在日本的漢字辭典中呢!日本女聲優「〆野潤子」的名字裡就有這個字。 |
| 3007 〇 | IDEOGRAPHIC NUMBER ZERO | 因為「一二三」都算文字,「二〇二〇」就該算4個字。 |
| 3012 〒 | POSTAL MARK |
CBETA 目前未使用此字元。 片假名「テ」演變而來 |
| 3013 〓 | GETA MARK |
CBETA 目前未使用此字元。 用來取代字型沒有、不能顯示的字 |
| 3020 〠 | POSTAL MARK FACE | CBETA 目前未使用此字元。 |
| 3036 〶 | CIRCLED POSTAL MARK | CBETA 目前未使用此字元。 |
| 303B 〻 | VERTICAL IDEOGRAPHIC ITERATION MARK |
CBETA 目前未使用此字元。 重文符號。 |
| 303C 〼 | MASU MARK |
CBETA 目前未使用此字元。 informal abbreviation for Japanese -masu ending 這是兩個字的縮寫符號, 通常用在結尾, XXXXmasu |
7 英數字以 word 計算,而不是 characters
例如
- 「1993」算一個 word,而不是四個字元。
- 「CBETA」算一個 word,而不是五個字元。
7.1 可以構成 en_word 的字元
| Unicode Name | Unicode Range | CBETA 使用字元 |
|---|---|---|
| ASCII digits | 0030-0039 | 0123456789 |
| Uppercase Latin alphabet | 0041-005A | ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| Lowercase Latin alphabet | 0061-007A | abcdefghijklmnopqrstuvwxyz |
| C1 Controls and Latin-1 Supplement | 00C0-00D6 | Ñ |
| 00D8-00F6 | Üàáâäæéêíïñóôö | |
| 00F8-00FF | ùúûü | |
| Latin Extended-A | 0100-017F | ĀāċēĪīōŚśũŪū |
| Latin Extended-B | 0180-024F | ȧ |
| MODIFIER LETTER APOSTROPHE | 02BC | ʼ |
| Combining Diacritical Marks | 0300-036F | ̐ |
| Greek and Coptic | 0370-03FF | Φ |
| Cyrillic | 0400-04FF | ДФх |
| Latin Extended Additional | 1E00-1EFF | ḄḌḍḤḥḳḶḷṀṁṃṄṅṆṇṚṛṠṢṣṬṭẖạụ |
| Number Forms | 2150-218F | ⅠⅡⅢⅣⅤⅥⅦⅧⅨⅩ |
| Enclosed Alphanumerics | 2460-24FF | ①②③④⑤⑥⑦⑧⑨⑩ |
| Latin Extended-C | 2C60-2C7F | CBETA 目前未使用 |
| Latin Extended-D | A720-A7FF | CBETA 目前未使用 |
| Latin Extended-E | AB30-AB6F | CBETA 目前未使用 |
| Halfwidth and Fullwidth Forms | FF10-FF19 | 0123456789 |
| FF21-FF3A | ABCDEFGHIJKLMNOPRSTUVWXYZ | |
| FF41-FF5A | abcdeiu |
7.2 連結符號
構成「英數字」以外的字元,都是分隔字元,除了以下字元例外:
| Name | Unicode | 字元 | 用例 | Note |
| APOSTROPHE | U+0027 | ' | don't | |
| HYPHEN-MINUS | U+002D | - | Saddharma-puṇḍarīka | 單獨一個 \- 字元不列入計算。 |
| MODIFIER LETTER APOSTROPHE | U+02BC | ʼ | paʼi |
7.3 各種用例
| 字串 | word 數 |
|---|---|
| 1993 | 1 |
| 10 | 1 |
| CBETA | 1 |
| MP | 1 |
| Saddharma-puṇḍarīka | 1 |
| isn't | 1 |
| ud-vsad,udvsyad | 2 |
| (ref taixu::vol:26;page:p102) | 6 |
| ~Caṇḍālakumāraka(+vā caṇḍālakumārikā vā) | 4 |
7.4 悉曇字 Unicode
目前 CBETA 尚未使用如下 Unicode 悉曇字,將來如果使用,也需考慮計算方式。
下面例子,應該只能算 1 個字:
𑖭𑖿𑖧𑖯𑖾 = U+115AD(𑖭), U+115BF(𑖿 ), U+115A7(𑖧), U+115AF(𑖯), U+115BE(𑖾)
圖: